Cloud Native Days France 2026
https://www.cloudnativedays.fr/programme
Note
En note, mes commentaires personnels sur les différents sujets. - Guillaume Coué
Agenda
| Time | Dur. | Room | Topic |
|---|---|---|---|
| 09:00 | 1h15 | Monet | Keynote d'ouverture |
| 10:30 | 45m | Monet | Stop the Fight : doper et unifier HPA, VPA et KEDA avec des métriques avancées |
| 11:30 | 30m | Monet | REX SNCF - Smells like Cloud Kubernetes : Notre Kube managé on-premise |
| 12:00 | 10m | Piaf | Cluster IA Air-Gapped : Concevoir, Sécuriser et Déployer une Plateforme Souveraine |
| 13:00 | 15m | Piaf | K0s distrib k8s |
| 13:15 | 30m | Piaf | REX Air France-KLM - Des chaînes applicatives aux chaînes OPS : Voyage vers le Cloud à bord d'Air France-KLM |
| 13:45 | 10m | Piaf | Sécuriser vos déploiements : quand kube-image-keeper sauve la prod ! |
| 14:15 | 10m | Piaf | Kagent sur Kubernetes : comment l'IA agentique vous rend 10 fois plus efficaces |
| 14:30 | 10m | Piaf | Inside Cilium: Deep Dive sur DSR (Direct Server Return) |
| 14:45 | 10m | Piaf | CA-GIP - Construire la Plus Grande Plateforme Grafana On-Premise d'Europe |
| 15:15 | 30m | Piaf | Sous le capot de Cluster API: concevoir et implémenter un provider d'infrastructure |
| 16:00 | 45m | Monet | REX Mistral AI - Construire un fournisseur cloud de zero: ClusterAPI dans le datacenter |
Glossaire, au cas où
- k8s : kubernetes
- KaaS : kubernetes as à service
- OSS : Open Source Software
- GPU : Graphical Processing Unit, aka carte graphique
- FPGA : Field Programmable Gate Array, un genre de processeur re-programmable pour un usage unique.
- SRE : Site Reliability Engineer/ing métier qui consiste à s'assurer que la prod tourne bien, dans des contextes DevOps pour assurer évolutivité et fiabilité.
- OPS : diminutif pour décrire les personnes travaillant à l'installation et au maintien opérationnel des serveurs, comme dev pour développeurs.
- CLI : Command Line Interface, une interface terminale qui permet d'utiliser un outil donné.
- airgaped : qui n'a pas du tout accès à internet, genre il y à de l'air entre le serveur et internet.
- SBOM : Software Bill Of Material, comme une BOM en industrie, mais pour des briques logicielles, la liste des composants de fabrication/dépendances, utilisée surtout dans les analyses SecOps
- PKI : Public key infrastructure, rôles/policies/logiciels de gestion des certificats / Certificate Authority.
- LZ : Landing Zone, zone d'atterrissage, jargon Cloud pour décrire la zone souscription/account... dédiée à un cas d'usage où un domaine.
- SPOF : single point of failure
- CRD : Custom Ressource Definition, ce sont des extensions de l'API kubernetes.
- Bare Metal : Un serveur physique sans couche de virtualisation.
Keynote d'ouverture
Contribuer aux projets OSS !
Exemple de pourquoi : La fin de Nginx ingress controller --> gateway api, car les maintainers du projet on stoppe
Demo sur le traitement des data issues des accélérateurs de particules
Cluster de 500 nœuds. 30k applications. 300gb/s actuellement et dans 1 an 5Tb/s de data d'event pendant les experiences. Stockage des data au sein du cluster sur Longhorn
graph TD
subgraph K8S
Kubeflow
LongHorn
end
LHC[Large Hadron Collider] --> |5Tb/s| FPGA[ML sur FPGAs]
FPGA --> |3Gb/s| LongHorn
Kubeflow --> |Analyze| LongHorn
Données de mesure issue de accélérateur de particule du CERN, LHC/Atlas
Construction de mini modèles AI (~100k paramètres), pour tourner rapidement sur des FPGA, le but faire le pre-processing des événement de mesure pour conserver cote Applicatifs standard un nombre d’événements plus minime. Via HLS4ML
Note
Techno intéressante, utilisable et utilisée aussi pour des application de type embedded, IoT / Véhicules autonomes, robotique.
Pour le traitement des data une fois récoltes utilisation principalement de Kubeflow et ses sous briques MLflow Kserve pour le training et serving, et JupyterLabs ,VScode et acces directement en ssh sur les pods pour les end users. Data sur Longhorn et Prometheus. GPU h100 intégré aux noeuds Kubeflow., séparés en partitions par MIG (NVidia Multi Instance GPU). Qui permet la reservation d'une portion de GPU lors de la creation d'une instance de compute Kubeflow Les user des personnes sont utilises au seins des pods, les end users ont sudo dans leur pods de travail, pour une meilleur acceptance des data-scientists. Les end users on access à l api k8s via leur user également, sur leur scope. ils peuvent également ssh sur leur pods, via credentials Kerberos. Access via l'extension k8s dans VSCode, pour remote access sur les pods directement dans l'IDE.
Sur les couche bas niveau, rattachement entre servers avec SLURM
Note
Je ne connais pas mais ça semble être un des outils privilégié des datascientists/dev AI.
Utilisation d'inifinity band pour le networking des GPU. CPU pinning, pour s'assurer que les CPU assignés par k8s à un projets sont bien sur le meme NUMA node qui porte les GPU.
GPU --> consommation de watt meme en idle. Utilisation de DRA, Dynamic resource allocation. Composable dis aggregated infrastructure, les GPU sont physiquement unplugged si non utilisées pour ne pas consommer d’énergie en mode idle.
DINUM et DGFIP : DSI de l’état français, stratégie numérique de l état
DINUM : Direction Interministérielle du NUMérique, la DSI de l’état DGFIP : Direction Générale des Finances Publiques
Contexte cloud prive de l’état
graph TD
subgraph OpenStack
subgraph kubo [Cluster Kubo 1]
ns[namespace n]
end
c1[Cluster Kubo2 ]
c3[Cluster de management]
end
DINUM --> |utilise| c3
DINUM --> |gere| OpenStack
c3 --> |provisionne| kubo
c3 --> |provisionne| c1
DGFIP ----> |instancie des applications| ns2 OpenStack internes à l’état, avec cluster k8s, usage de CAPI(Cluster API) pour le provisionnent de clusters sur OpenStack - ministère de l'intérieur - DGFIP --> Calcul des imports Plateforme certifiée Label SecNumCloud. Les applications principales hébergées sont
- France connect - Démarche simplifiée (les impôts) - App ministère - Tchap : messagerie instantanée du secteur publique - Viso interne, docs interne, ... La DINUM fournis un KaaS pour une 40 aine d’applications fournis par l’État.
Distribution k8s Kubo, la DINUM s'est fait sa propre distribution k8s hardened à ses besoins.
Note
J'ai cherché un peu si cette distribution était elle meme OpenSource, mais pour le moment on dirais que non. Assez impressionne par l’État de maturité de la DINUM sur le sujet, il sont mieux outilles qu'un grand nombre d'entreprises privée
- Hybride
- Namespace as à service
- la DINUM gère tout pour les end users
- base sur CAPI, donc compatible tout hosting
- postes d admin sur NixOS, os immuable
- Autres briques de la stack intra k8s:
- Capsule pour le framework de multi tenancy et les policies associées
- Sveltos pour le déploiement d'addons depuis le management sur les clusters metiers
- Kyerno pour l'application des policies
Scaleway
Tech lead, Jean baptiste kempf
(Advertisement)
Vrai souveraineté : Compile everything Kernel linus, propre stack de conteneur,...
Mise à dispo de SKD, provider TF, console on top of GO api.
Fait parti de Iliad.
Note
Une option de plus à envisager quand on nous demande du cloud souverain sur des projets, leur portefeuille de service à l'air bien plus complet qu'il ya 2 ans
Table ronde
- qu'est ce qu on doit regarder sur les CV?
- moins de tech pure, plus de skills de prod, le monitoring, les archi haute disponibilité
- diverse, avoir une équipe avec skills diverses, data, dev, secu, infra,...
- Comment on-boarder des gens
- donner des outils pour aller taper directement sur lecosysteme, sans forcement qu ils aient à comprendre toute la stack.
- rencontrer les autres equipes
- Estce que le dev vas etre responsable de tout où il faut splitter le roles, dev , devops, ...
- peu importe les roles, il faut des RACI, sinon personne prend l'ownership, mais il faut le definir des le debut, et accepter d'etre contacter sur son scope
- you build it you run it marche bien, sur la partie applicative.
- one ne peu pas demander au dev d'etre responsable de ce quils livrent si ils ne comprenent pas la stack total, il faut former les devs à l'ops.
- ideal vers lequel il faut tendre checker 'team topologies'
- est-ce que une bonne doc ca ne ferais pas l'affaire
- la doc c est dur car il faut la faire vivre, mettre la doc dans le code ? en plus de la doc, mettre des guardrail dans la ci, pour s assurer que ce qui ship est compliant avec les plans initiaux.
- pour ce qui peut etre fait en auto, faire en auto, pour la liste des ressources par exemple.
- trop de doc pas naviguable est pas bon non plus. il faut delete les docs outdated.
- k8s c'est trop dur, vrai où pas, metter en place un portail qui gere toute la stack pour les devs c'est une solution ?
- il ne faut pas sur outiller via un IDP, ne pas en faire la premiere etape de mise en place d'une plateforme
- la fourniture de framework appicatif est bienvenue par les devs, car ils n'aiment pas faire de helm charts.
- Si trop restrictif, cafait du shadow it
- il faut laisser un peu de mou
- il faut que tous le monde soit capable de debug, siil y à des 100aine d'applis il faut mieux etre assez uniforme.
- les astreintes, le you build it you run it
- ce qui marche, les devs sont en binome d un sre/ops, pour qu ils aient l'impact de leur build sur le run. meme sans etre on call
- on à jamais juste une personne on call
- les pro tips, voeux
- que les équipes se parlent sans silot, entre les devs et les sre. lol comme les devs et les ops avant
- aller voir les Communautés de pratiques
- stay curious, experiment
- Eviter que les devs gèrent les Helm charts, sinon ça explose, centraliser ca.
Note
A écouter cette table ronde, compose de leader dans le domaine, on à l'impression que bien que les stack technologiques aient beaucoup évoluées en 20 ans, on se retrouve toujours avec les meme problèmes l'ownership (RACI) et la communication des silos. La ligne s'est juste déplacé de Dev vs Ops à Dev vs SRE/DevOPS.
Numspot La plateforme de Service cloud Data et AI
(Advertisement)
GA depuis quelques mois. Socle 100% open source
Écosystème à date - ecosystem k8s, PostgreSQL, container registry, secret manager, GPU , VM, stockage, réseau - Souverain France SecNumCloud - Polyvalence, provider Terraform disponible
Note
Yet another cloud souverain, i guess
TOSIT The open source i trust
Tosit, association française autour de l'usage de l'open source entre les entreprise françaises et les ministères qui le souhaitent. Devenir acteurs de l'Open Source entant que consommateurs via des ateliers.
Openstack, k8s, PKI, AI, Data, ...
Le but de l'initiative ? Faire des REX entre entreprise, travailler sur des outils communs
Note
J'ai vu que Orange fais parti de cette association, il serais bien de voir en interne ce qu'on y apporte et sur quel sujets, qui sont les acteurs internes dans cette communauté
Stop the Fight : doper et unifier HPA, VPA et KEDA avec des métriques avancées
Les problèmes entre
- HPA : horizontal pod scaling --> pod replicas - VPA : vertical pod scaling --> pod sizing - KEDA : event based scaling --> events
HPA se base sur un metric server de base, il faut mieux passer par des metric Prometheus, car plus rapide à remonter des metrics.
VPA collecte 1 sample par minute, avec de l'historique de sampling par jour, et des halflife des journées précédentes, dans le but de définir des patterns d'usage quotidiens, réagis pas trop bien au pics, et il doit redémarrer les pods.
Note
A verified, mais il me semble que avec k8s 1.35, on peut maintenant faire du scalling vertical sans stopper un pod.
Keda crée un objet HPA under the hood. Suis des Scale Objects genre des queues Kafka, comme pour HPA, il faut mieux utiliser des metrics de Prometheus pour Keda aussi.
Il ne faut pas qu'une metric soit utilisée par plusieurs scalers, sinon: conflits, oscillations, restarts.
Exemple si on met HPA et Keda sur la meme metric de CPU, Keda vas voir des requets arriver et faire popper des pods, mais la règle HPA aussi sur le CPU, vas kill les pods car pour lui il n'y à pas de besoins immédiat, ca oscille.
Ca peut être pareil avec du VPA+HPA, HPA scale, les usages par pods baissent, VPA recommande moins de CPU, les pods restart pour scaller, ont à du throteling, qui fait scaller HPA et ca boucle.
Plutôt utiliser des metrigs Leading vs Lagging
| lagging | leading |
|---|---|
| utiisation cpu | ratio de throttling cpu |
| queue depth | queue depth + growth rate |
| latence moyenne | p99 de latence |
Reco: pas de scaling sur la mémoire,il faut la right sizer sizer comme pour l'usage maximum d'un pod.
Utiliser Prometheus adapter si pour HPA, et le connecteur prom natif pour Keda.
voir https://github.com/google/cadvisor
Note
Content de voir que l'utilisation de la cli k9s fait l’unanimité pour interagir avec des clusters. Ces différentes problématiques de scalling sont importante car, à delà de la scalabilite pour répondre à des besoins imprévus c'est un des axes majeurs de finops une fois qu'on à un cluster qui fonctionne, pour que les noeuds scale down, il faut que les pods scale down.
REX SNCF - Smells like Cloud Kubernetes : Notre Kube managé on-premise
Yann Rotilio, Matthieu Strohl, Etienne Germain
Contexte
15k train daily eSNCF Solution - 2000 apps - 3 Cloud providers - 4 datacenters Service conteneurisation - depuis 2018 - 14 inge - 200 apps - 7 clusters à la base, maintenant 25 clusters - 60k containers - Stack on prem l’idée et de proposer sur le on prem un service ISO à celui des cloud providers.
Step 1 : RKE2
Premiere iteration de k8s on prem VM generiques, Ansible et Terraform, zone airgaped et DMZ. 1 an de dev, 1 mois pour avoir un cluster, 7 clusters en 4 ans. ExcelOps et TicketOps, car provisionnent et ops à l'ancienne en zone très fermé, tout à la mano.
Step 2 : OpenStack
A permis de consommer facilement l'infra de base de d'y déployer des RKE2 plus simplement.
Step 3 : Talos
en 2024, switch sur Talos OS car - rapide à setup - hardened - scalable
Les cluster Talos on une machine outils pour setup les clusters sur Ubuntu avec Talosctl, et après un control plane avec 3 nœuds, et 2 node pools de 2 nœuds chacun, via OpenStack. Problèmes de gestion du Day2 en mode script Talos depuis la machine outil
graph TD
subgraph OpenStack
Terraform
ubuntu[Ubuntu with talosctl]
subgraph Cluster [Cluster Talos]
direction TB
subgraph cp [Control plane]
t1[Talos 1, 2, 3]
end
subgraph wn [worker nodes]
t4[Talos 4, 5]
end
end
end
Terraform --> |Creates| ubuntu
Terraform --> |Creates| Cluster
ubuntu --> |Manages| t1
ubuntu --> |Manages| t4
cp --> |controls| wnStep 4 : ArgoCD
Passage sur un cluster de management central qui gère tout le parc - cluster autogéré - app of apps pattern - Le cluster central gère pour les autre clusters toutes les ressources de bases - CNI/CSI - monitoring - security/external secrets
Step 5 : CAPI Cluster API
Ajout de Cluster API pour initier les cluster Talos sur OpenStack - node autoscaling - auto healing - déclaratif - via des opérateur sur le cluster de management

Le pet est mort, vive le cattle
Les problématiques
Mette en oeuvre un provider pour cluster api il faut - components.yaml - metadata.yaml Utilisation de ORAS pour stocker les configs de providers en OCI. Centralisation des config cluster API dans Harbor pour configurer ses providers depuis le cluster de management.
Il y à un seul fichier yaml qui définit un cluster applicatifs du point de vue du cluster de management. Il est converti en Helm chart, pour que Argo CD le gère comme une ressource normal.
Pour la gestion des secrets, problemo Le provider contrôle plane de Talos génère des secrets au moment de la creation via CAPI Cluster API, qui sont nécessaire ensuite dans les namespace ArgoCD Leur brique maison Capix, qui est un controller, consomme les events de creation de cluster par CAPI pour les récupérer les secrets et les ajouter dans le namespace ArgoCD. Capix est bientôt open source.
Le fichier de description des cluster est ingéré par Terraform et pousse sur ArgoCD.
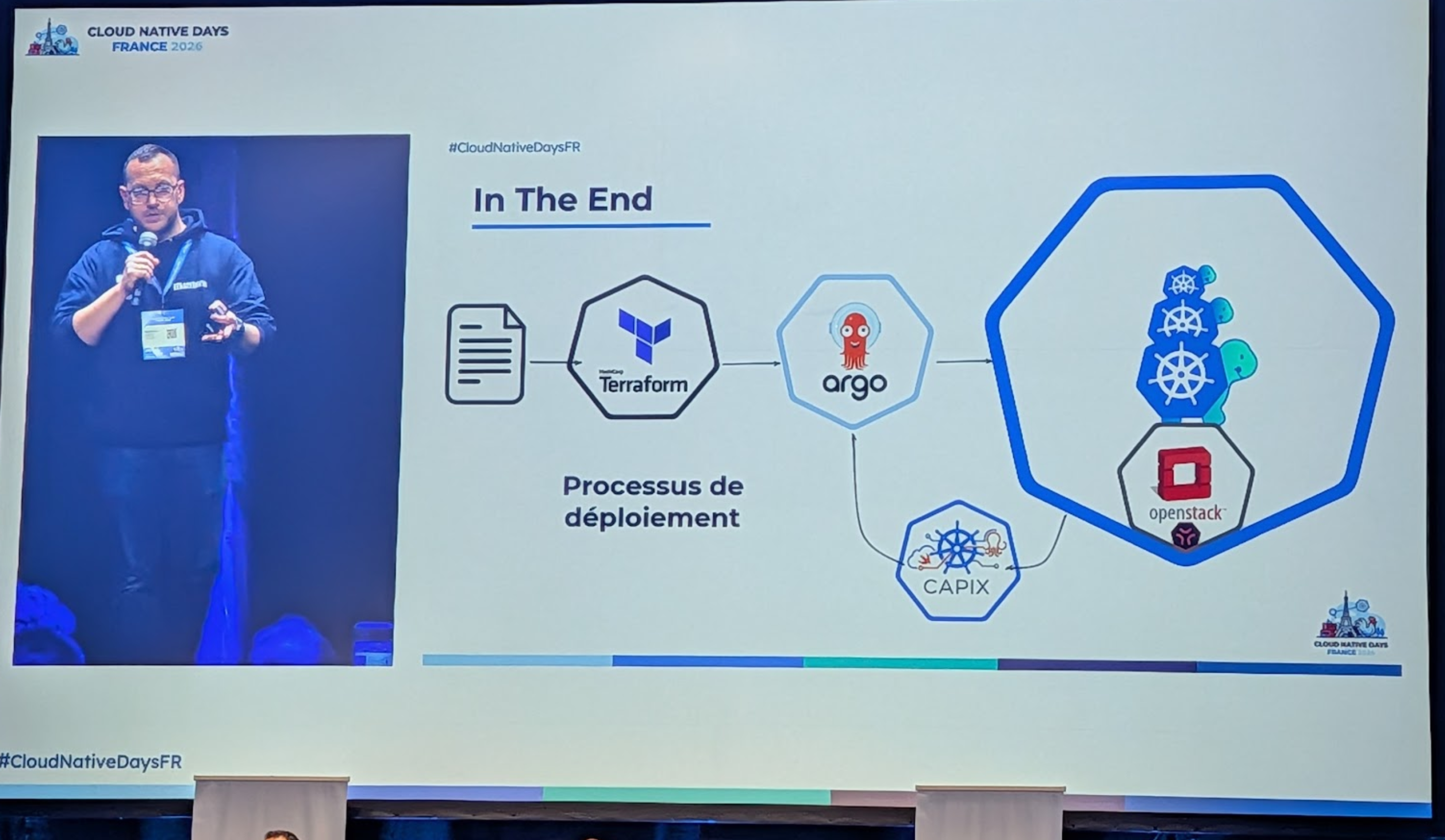
A part Terraform qui gère l'initialisation, tout le reste et sur le cluster de management.
Note
Vraiment un super REX, on voit que le pattern de cluster de management semble être le way to go, quel que soit les technos. Comme le Hub&Spoke dans les archi Azure.
Cluster IA Air-Gapped : Concevoir, Sécuriser et Déployer une Plateforme Souveraine
Dassault Systèmes Outscale Stephane Robert, Christophe Morvan
Pourquoi airgapped - protéger les données - respect des règles de diffusion C3 (classification des données confidentielles si je comprends) - la sécurisation de la supply chain et des deploiements
Pas d'internet, pas de cloud service , pas d'images non signées Une zone autorisée pour l'ingestion dans le SI, le bridge, un genre de DMZ
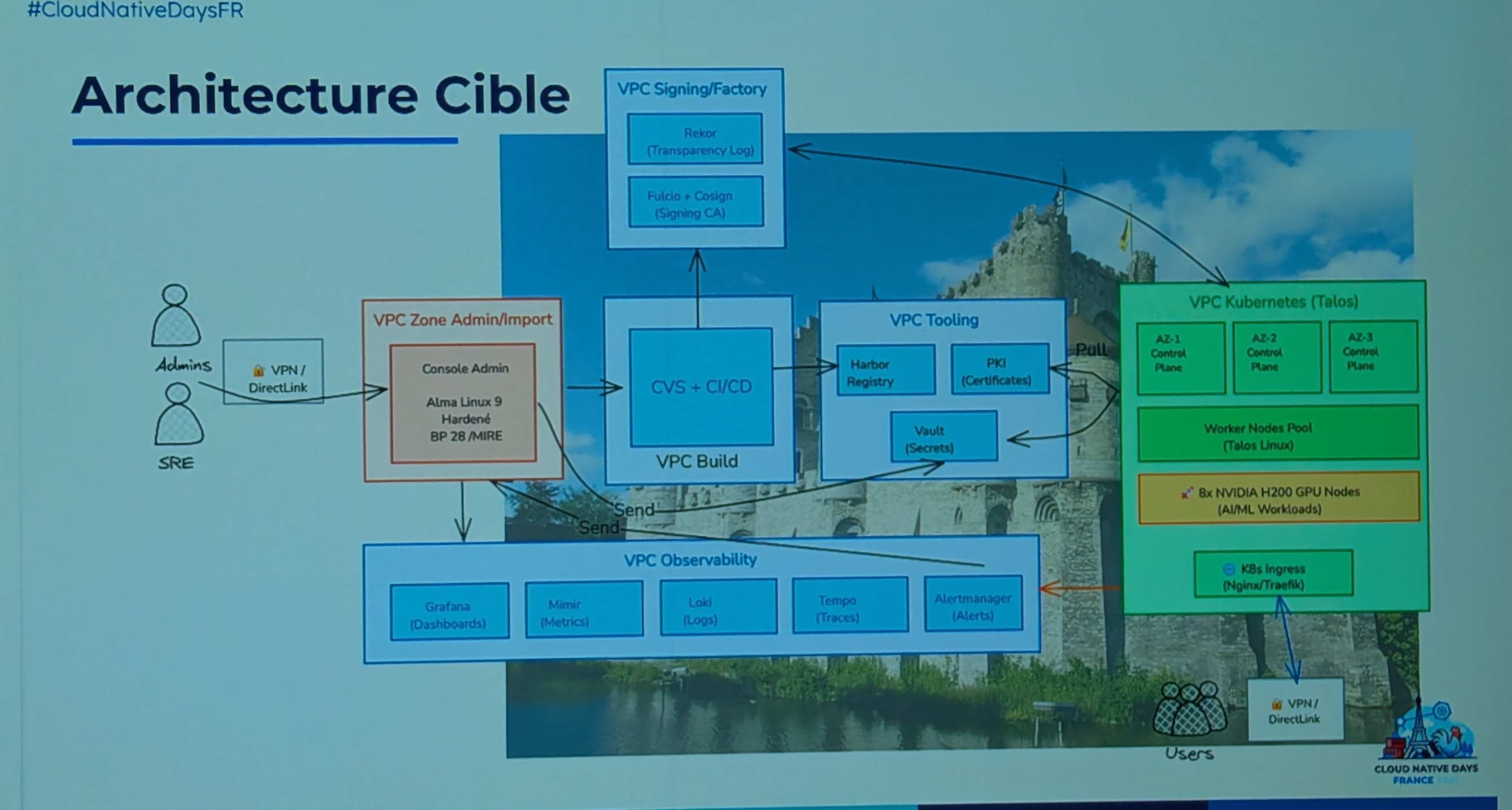
stack base sur Talos linux, mais il faut prévoir d'apporter les drivers et les images Talos au sein du SI.
Packer et Ansible pour construire des images d os Talos et y ajouter les drivers Nvidia, nvlink nvidia, device plugin, gpu operator, csi/ccm
On à ensuite une conf Talos GPU ready.
Pour la partie SecOps, utilisation de SBOM pour toutes les briques. Et d'une registry interne.
pour la PKI, creation d'une PKI OpenBao, qui fait un root CA, et fait un intermediate platform pour le registry, un pour le cluster, et un intermediate application pour les workloads applicatifs.
Point d'attention: Il faut être très strict sur les versioning et mettre à dispo des bundles fonctionnels en l’état.
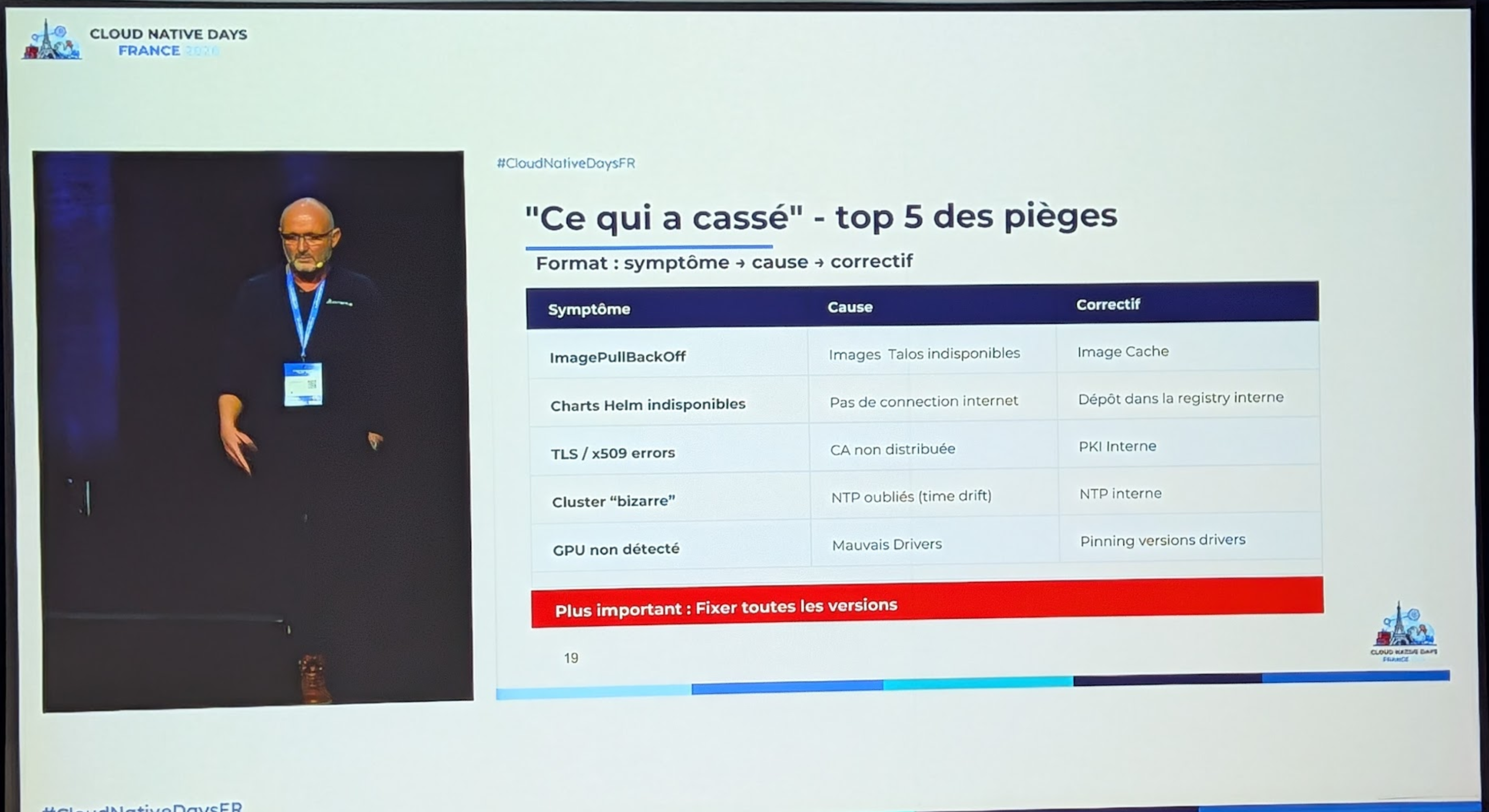
Note
Intéressant sur l'aspect airgapped , car ça revient assez souvent sur nos contextes, dans l'industrie/armament. Ce que ca montre, c'est qu'il faut d'abord avoir une supply chain solide avant de se lancer dans ce type de déploiement. Et ne pas s'attendre à fournir tout les versions/librairies disponible. dommage que la présentation soit si courte, elle manquait un peu de contexte sur le vrai usage qui en est fait dans ce scenario
K0s distribution k8s
- k0s: lightweight k8s distro, single binary
- k0sctl : la cli associée, pour gérer les cluster de façon declarative, via du yaml
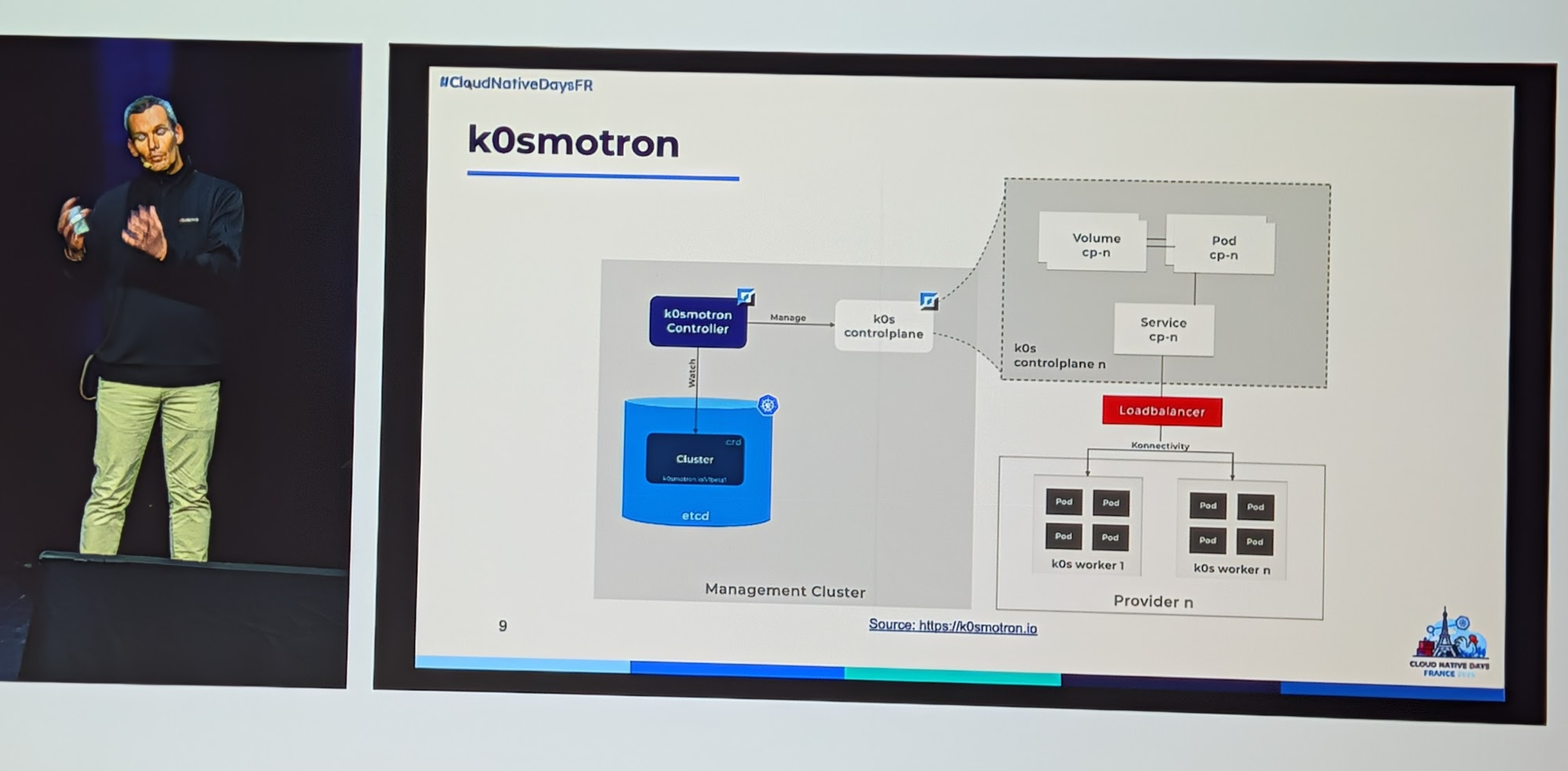
- k0smotron : on à un cluster de management, et on fait popper des control planes dans des pods du cluster de management, on vas rajouter des workers sur d'autres machine, c'est une CAPI provider, donc il peu s'appuyer sur plusieurs infra provider pour faire popper des noeuds kub via cluster API.
- cluster
- control plane
- infrastrcuture provider
- machinedeployment
- bootstrap
- kordent : permet de gérer des application sur une flotte k0s, et de template des deployment kub sur des k0s
Note
A voir si c'est utilise / suivi. On dirais un peu un #k3s qui veut tout faire en meme temps, où on melange de la gestion de cluster, du gitops à la flux. J'ai peur à premiere vue qu'une stack qui fasse tout à la fois ne fasse pas tout bien à long terme. Peut être l'utiliser à la place de #kind pour le dev local.
REX Air France-KLM - Des chaînes applicatives aux chaînes OPS : Voyage vers le Cloud à bord d'Air France-KLM
Caroline de Vasson
2500 appli metier, 540 appli techniques nécessaire aux vols 3 data centres 1 cloud prive : pas trop utilise pour le moment, c'est pour les application old school qui nécessite des hardware particuliers 2 cloud public GCP et Azure 1000 employés qui font de l'ops
la forge historique ci/cd : git, #sonar , #bamboo, #nexus Cette chaine fonctionne bien et pousse du code en production, mais problemo, pas de provisioning d'infra automatique, c'est du ExcelOps via demande excel traitées par les ops
L'ere du cloud
Le but était - de faire monter en competences toutes les équipes, cart out le monde n’était pas au niveau - limiter l adherence aux cloud providers, pour ne pas se vendor lock - accélérer le time to market
Automation 1.0
- Postula "you build it you run it"
- offrir un catalogue de service infra
- les dev demande un service IT, via ticket, qui lance du Ansible, qui lance du GitHub Actions, qui provisionne en Terraform
- Problemo car encore beaucoup d'actions manuels, et de gestion de fails de pipelines, à gérer à la main par les Ops
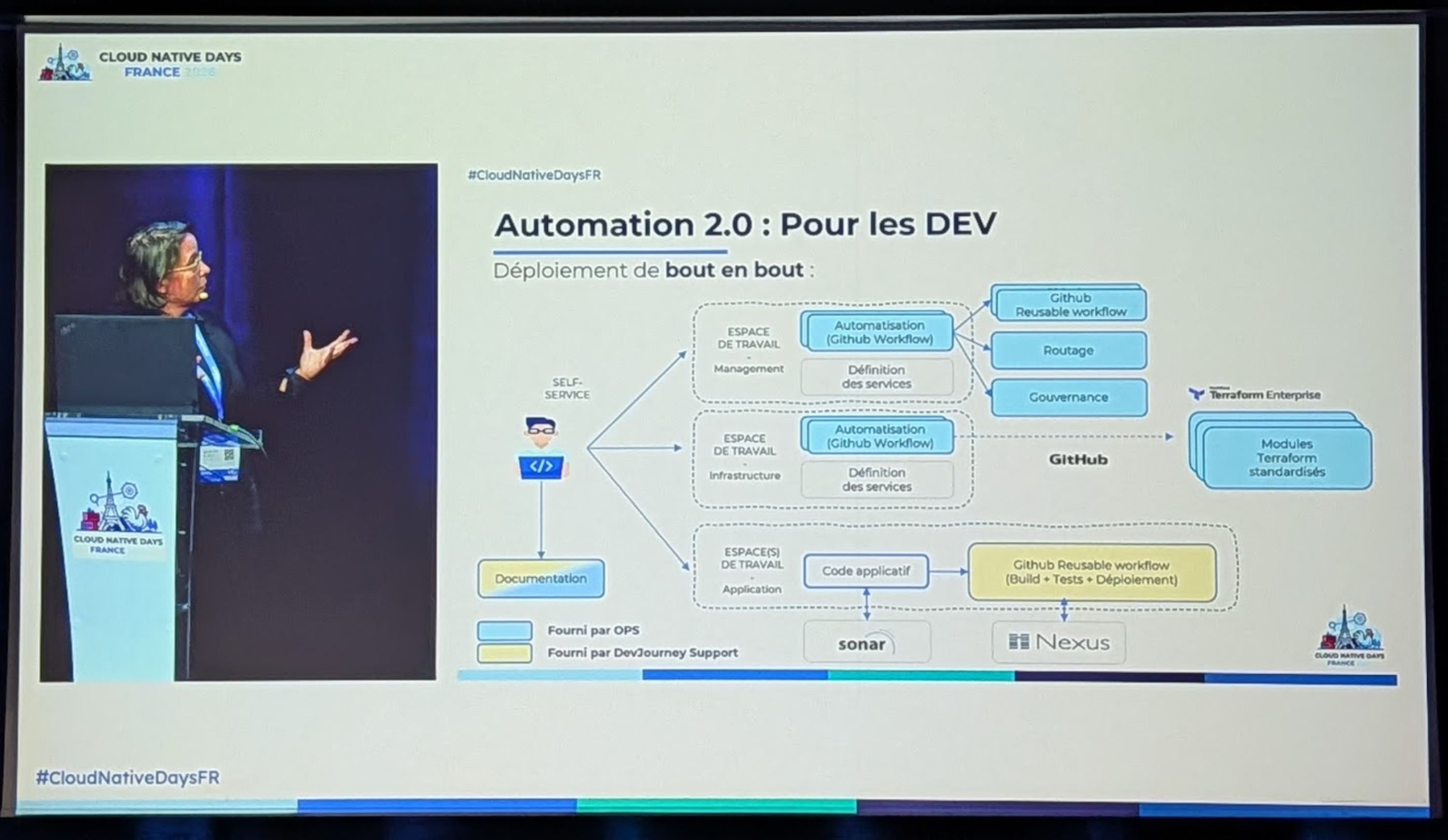
Automation 2.0
- simplifier le cycle de vie
- encore en you build it you run it
- abstraire la complexité
- unifier l'experience developeur
- nouveau process
- mise à dispo d un repo de management aux dev par lz/spoke
- routage , dns, certificats
- gouvernance
- modules Terraform standardises
- workspace shared services Terraform pour les service simples
- certain service on leur pipeline Terraform dédiées, comme les AKS (Azure Kubernetes Service) our les app gateway qui on des cycle de vie plus complexes
- PAS D UPGRADE IN PLACE DES AKS, que des blue green de clusters.
- decoupage de la lz en workspaces terraform
- mise à dispo d une documentation sur comment utiliser les services et modules
- les devs ne voient que GitHub et des workflows, en full autonomie sur l'usage
- Contrôle de coherence entre les service demandés dans le Terraform et les service Valides par la CMDB / CCoE, directement au sein des pipelines GitHub.
- mise à dispo d un repo de management aux dev par lz/spoke
- des qu'on propose un service il faut prévoir qu il vas évoluer, donc l'équipé DevOps doit maintenir la doc et les modules. Ils informe et accompagnent ensuite les projet metiers sur la mise à jour de leurs service / modules.
Note
Hyper intéressant, dejas sur l'approche de vrai autonomie des équipes de dev, et assez etonné par la gestion du cycle de vie AKS, je n'aurais pas pense que faire de l'upgrade in place pourrais être tant un problème qu'il faille gérer les AKS dans un state à part. Il faut que je regarde plus la partie Terraform workspaces qui je ne connais/utilise pas.
Resenti des Ops vs Dev
| Role | Points Positifs (Plus) | Points Négatifs (Moins) |
|---|---|---|
| Dev | - Rapidité- Automation- Collaboration | - Courbe d'apprentissage- Responsabilité- Complexité |
| Ops | - Standardisation- Traçabilité- Scalabilité- Collaboration | - Perte de contrôle- Adaptation |
final où pas ? non un chaine est un produit, avec amelioration continue, nouveaux services mise à dispo régulièrement.
Note
Ils utilisent les providers Terraform par défaut, mais avec des limites pour brider les versions à celles qu'ils definissent comme compliant.
Sécuriser vos déploiements : quand kube-image-keeper sauve la prod !
paul laffitte , enix
KUIK Kube Image Keeper Outil de gestion des images au sein des clusters kub Les registries sont des SPOF - pas de fallback - images deleted - quotas
Les images doivent être - redondantes - observables
Concept clés - avec un kind ClusterReplicatedImageSet, avec une definition d image qui peut venir de plusieurs registries à la fois - mirroring d'images, vis ClusterImageSetMirror, les images pulled d un cote peuvent être pushed ailleur Utilisation de mutating webhooks pour remplacer les images demandes, au moment de la demande de creation des pods
les CRDS - ImageSetMirror pour les namespaces - ClusterImageSetMirror pour le cluster - ReplicatedImageSet pour les namespaces - ClusterReplicatedImageSet pour le cluster
Pour le moment, pas de garbage collect / cleanup, pas de prio entre les registries.
Note
Cool, ça peut en effet sauver la prod si on depend des registres pas forcement en forme, genre un vieux Nexus cough cough A voir l'overhead de configuration que ca implique sur une utilisation generalisee.
Kagent sur Kubernetes : comment l'IA agentique vous rend 10 fois plus efficaces
Amine AIT AAZIZI, SRE et cloud archi Les agents ai sur k8s
Pourquoi des agents sur k8s : bcp d'outils, bcp d'intervention
Kagent : projet en cncf sandbox
Framework : dashboard, cli, controller, backend base sur google ADK
Definition d'agents AI, au sein du cluster via une crd/kind Agent, en yaml - ajout des MCP tools
Core concepts - Agents , via la CRD - LLM providers diverse via ModelConfig
Dans lidee on definie un agent auquel on donne les bon outils pour monitorer le cluster, et par exemple ouvrir des PR de fix sur les repo de definition de ressources kub.
Il y à un subproject #khook, qui fait pareil mais sans humain dans la boucle.
Note
OK, si on à un manque de personnel ça peut être utile, à minima pour le troubleshooting meme sans action derriere, mais perso je trouve que donner un acces kubectl à un agent local fait dejas le taff.
Inside Cilium: Deep Dive sur DSR (Direct Server Return)
Alexis la goutte, kubernetworker
Cilium : - CNI principale à date, - securisation des ys, l4 à l7 - remplace ment de kube-proxy via ebpf - hubble pour l observabilite reseau DSR : - un client parle au load ball, qui renvoir au serveur, et le serveur parle direct au client - la où de base, cest l ip du load bal - via cilium dsr, meme si on plusieurs noeuds, on peut s assurer de renvoyer le l ip du pod serveur source au client - le but est que dans le trafic backend vers client, on n ai pas les IP des pods cilium en source IP, du point de vue du client. Cilium à plusieurs mode de tunelling - Protocole GENEVE --> tldr il faut mieux utiliser ce mode la. - Protocole IP
Cf la documentation DSR
Note
Rien compris, on atteint le limites des mes compétences réseaux.
CA-GIP - Construire la Plus Grande Plateforme Grafana On-Premise d'Europe
Maxime Calves, Credit Agricole
La problématique, plein de plateformes Grafana dans des versions differentes.
En 2023 10 users, en 2025 6500 users
La plateforme - plusieurs projets GitLab avec des images docker, des helm, des projets ArgoCD - un cluster qui sur lequel on deploy les Grafana - des DB PostgreSQL pour la persistante sur une stack HCI à part.
A la base, pas d'uniformisation, il y avais de l’observabilité, mais pas d'uniformisation. Car absence de produit / plateforme maintenue par une équipe.
Le but, faire de Grafana un Produit interne au meme titre que les autres solution internes.
Le end user fait un formulaire , qui lance via un script dans GitLab ci, qui fait des calls API à Grafana pour créer des teams, folder, ...
Travail avec les équipe ops qui travaillais dejas via ces outils, pour y intégrer les source de données utiliees à tout le monde. Mettre à dispo les bonnes sources pour avoir une bonne adoption de la plateforme.
Différents types de users, qui peuvent interagir différemment avec la plateforme en fonction de leurs attentes. des possibilité de faire à la mano, où de passer via des yaml de déploiement et des repos. Il faut qu elle soit accessible.
Chaque équipe à la main sur ses source de data et fait ses tableau de bord par besoins. Les users sont owner de leur viz, full self service.
Mise en place de beaucoup de com, des articles, des release notes, des webinars, un channel teams, ...
Car la plateforme vie par ses end users, pas par la tech. Une plateforme sans users et une voiture sans volant.
L'adoption se fait d elle meme. Un outil ne se scale pas, un produit si.
Note
Ok intéressant, un très bon talk de product owner. Maintenant il faut trouver des PO motivés comme lui chez tous les clients !
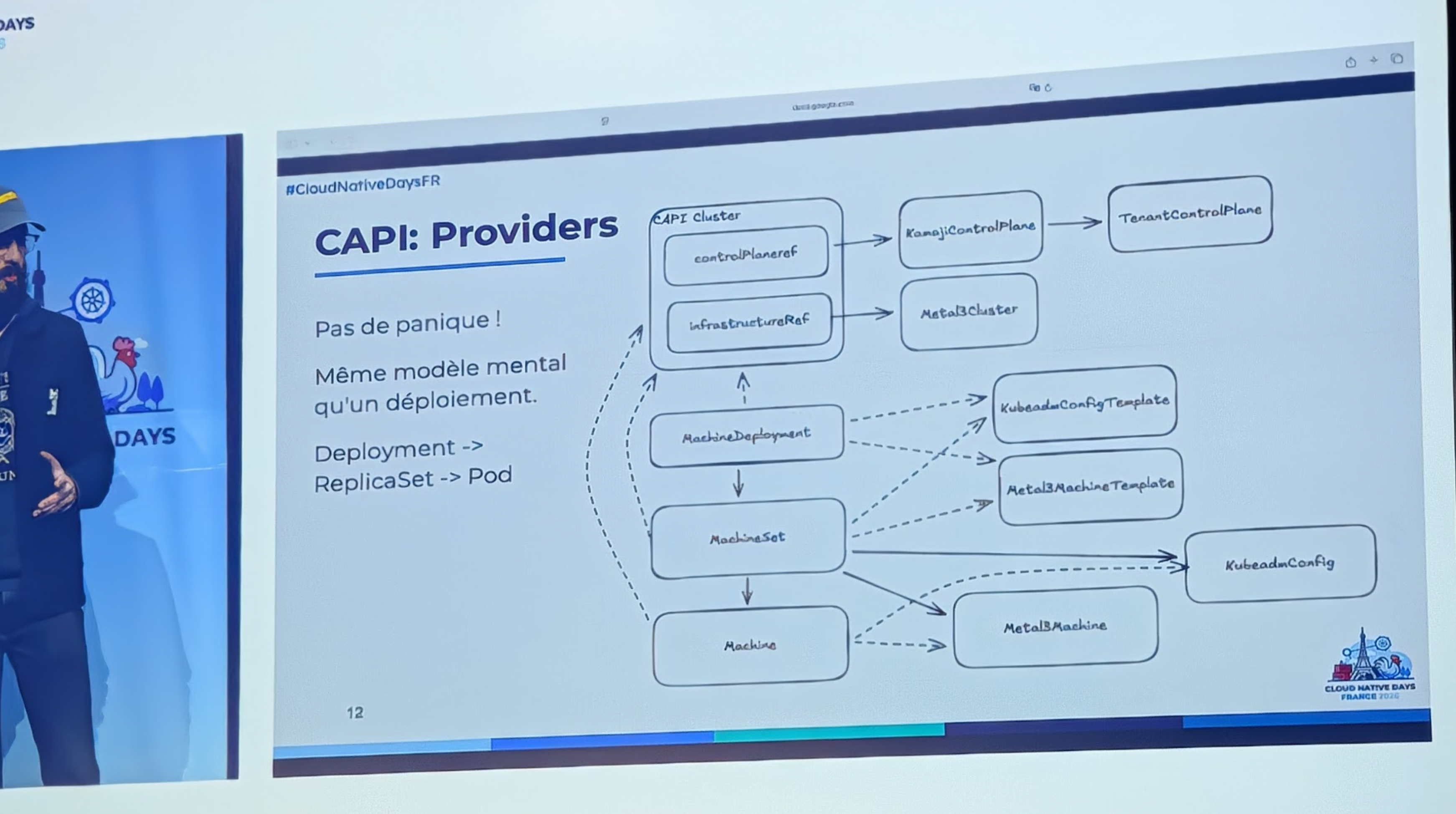
Sous le capot de Cluster API: concevoir et implémenter un provider d'infrastructure
La base de cluster api CAPI. - des CRD et des controllers pour gérer des cluster kubernetes dans kubernetes. - un provider cluster API est un opérateur kub, qui vas pouvoir traiter les CRD demande par les ressources CAPI, - le provider d'infra : parle avec les stack d infra , aws,gcp,nuta,vmware,... - le providers bootstrap : mettent place les distro k8s, talos, k3s, ... - le provider control plane : qui instancie le controle plane k8s : talos, k3s ,...
Il faut donc pour apporter ses providers, il faut ramener en plus de CRD Core de CAPI, il faut étendre ces CRD pour la stack sur laquel on veut provisionner, ainsi que le controller pour ces extended CRD.
Pour faciliter la creation, s'appuyer sur Kubebuilder qui facilite la creation d'un opérateur kub, en go. Et importer le SDK go de notre infra provider, si elle existe.
On peut ajouter ses propres champs qu'on veut permettre à l'utilisateur d'utiliser lors de la creation de ses clusters. comme, le vnet, la zone dns, ...
Les kind à implementer - cluster - machine - machine template Les controller à implementer - Cluster Reconciler - creation d un scope avec les contextes api de l'infra et de la CRD cluster - ajout de finalizer sur les secret aligne avec le cycle de vie de la CRD cluster - renvoie des address controle plane sur la crd cluster - Cluster service, on définie des reconcilers pour tous les service sous jacent pre requis pour le setup du cluster. - vpc - gateway - load bal - domain - Machine, meme méthode de reconciling pour le provisionnement des machines.
Pour l'operator, il faut builder une image dédie, avec les binaire capable de parler avec notre stack d infra.
Note
Cool, une bonne demonstration de comment on construit son provider. Il faut vraiment que je m'y mette à ce CAPI ! et clusterctl. Laurent Nominé avais raison. Par defaut, les cluster via CAPI n'ont pas de CNI/CSI/..., il faut prevoir des les ajouter.
REX Mistral AI - Construire un fournisseur cloud de zero: ClusterAPI dans le datacenter
Leonard Suslian, Antoine Roy
KaaS en bare metal Mistral Compute: initiative d'avoir un cloud europeen, avec du materiel GPU Nvidia à date, fournir une offre complete de bare metal à du SaaS mistral studio et entre les deux du KaaS.
Note
un max de GB200 :o
Passage via le provider infra Metal3.
Comment on crée le cluster de management? utilisation de la fonction Pivot, pour cloner le cluster avec CAPI local vers une cible.
Le premier cluster CORE à toutes les CRDs CAPI. Et on rajoute le provider - Infra Metal3 - Kubeadm pour bootstrap - Kamaji pour le control plane
Le cycle de vie des cluster de CAPI est comme une app normal.
Metal3 pour le bare metal - CAPI provider Metal3 - Metal3 operator :gère les ressource de Metal3, mais ne les provisionne pas, il les définies. - Ironic, gère quels machines physiques on apporte à Metal3, le provisioning physique des machines est fait par ce service
Le cycle de déploiement est le suivant : CAPI core -> Metal3 -> baremetal host -> Ironic -> pxe -> os=> node kube
Kamaji - gestion de control plane dans un cluster qui vas porter les control planes de tous les clusters crée par la stack CAPI. - Les control plane sont isolés comme celas, uniquement via l'api server. - permet d avoir de la haute disponibilité, sans ajouter 3 nœuds bare metal par clusters.
Il on fait un opérateur on top de tout ca, pour avoir une CRD pour faire leur propre ComputeOperator, via Kubebuilder encore une fois.
Leur CRD : managedCluster. avec des reasons pour toutes les étapes du cycle de vie d'un cluster k8s, la CRD une fois definie en yaml fait 30 lignes à peu prêt.
En frontal de l'operator, une api customer facing avec un IDP.
Note
Une sacre stack :o
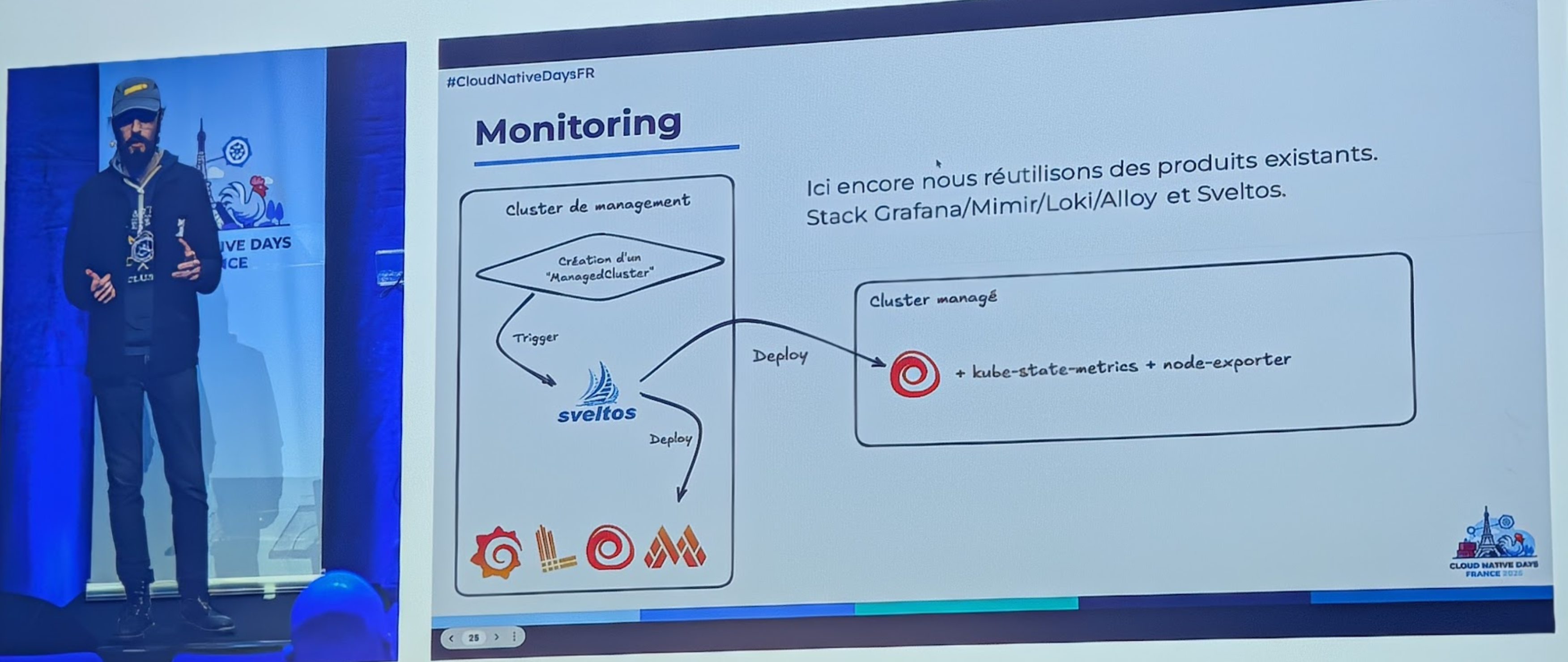
Le Monitoring - Fulls stack Grafana Alloy - La kub monitoring stack - Si on fait du KaaS, il faut du monitoring - Cluster de management, qui trigger via Sveltos un déploiement des Alloy avec kub state metricset node exporter - Le Grafana , Loki, Mimir sont sur le cluster de management central ! pour ne pas être aveugle en cas de pb. ils sont instanciés pour chaque tenant/client qui posede un managedCluster, donc si un client à 10 cluster il à une instance de monitoring unique pour tous ses clusters.
Pour la gestion des workload, utilisation de SLURM . Slurm + kub = Slinky Il y à des ressources dédies à SLURM , le controler les nodeset, loginNodes Pour ca aussi, il on fait une sur couche qui encapsule SLURM .
Note
Je ne connaissais pas cette techno SLURM mais entre Mistral et le CERN ca à l'air d’être un outils apprécie des data scientists.
Les problemo
Cluster hybride x86_64 et arm64, sur les serveurs Nvidia, Grace fournis par nvidia, il y à de base des cpu arm64, dont pour toute la partie Metal3, il faut gérer les builds arm, pas de support Ironic dans Metal3 pour arm de base.
Mise à l’échelle, ETCD est le maillon faible. Avec bcp de nodes, les leases et events explosent et pète le ETCD, sur des cluster à 4600 nodes. Solution -etcd-servers-overrides permet de passer certaines ressources sur d'aures clusters ETCD. Ils ont donc multiplie le nombre de serveur ETCD, genre 5 cluster ETCD différents, mais il faut partager les CA mtls. Ils ont fait une contrib sur Kamaji, de dataStoreOverrides, pour pouvoir dériver des events sur des ETCD secondiry. Avoir que les ressources kubernetes dans les ETCD primary.
Hardware Shenanigans RedFish, BMC, PDU, DPU, DHCP, iPXE, VXLAN, OOB, DDN,....
Note
Et oui, en baremetal pas de DHCP par default.
Q&A
Pourquoi il n ont pas remplace ETCD ? ils y on pense, et veulent tester du PostgreSQL et Kine, mais le sharding marche.
Pourquoi bare metal? parce que dans le cas de l AI, en tout cas en training, on consomme toujours 100% du host, donc pas davantage à etre en VM. Et les perfs bas niveau sont la.
Qu est ce qui se passe si on perd le secondary ETCD ? ça casse pas tout askip
Le delete d'un managed cluster ? il y à plein de cleanup, decom des nodes pools cluster API, ils utilisent des petits host de cleanup des Machine bare metal. Puis tear down du control plane kamaji.
Pas de PB de nombre de pods par hosts? Ca arrive pas sur les workload ai, que sur la ci/cd on atteint les 110 pods par nodes. Mais pour les GPU on est à 10 pods par noaueds. Et come il y à SLURN un cluster slurn est dans un POD, donc ok.
CNI ? Cilium, mais sans encapsulation vxlan, usage auto-direct-node-route, le pod cilium peut prendre chere. 30go/ram
OS immage des noeuds ? pas immutable, car Nvidia drivers certifies pour Ubuntu 24.04 par ex, pour le support Nvidia. Mais si il pouvais Kros où Talos.
Technos à checker
- K0s : Distribution k8s single binay pour du cloud, bare metal où edge/iot
- Capsule : framework de multitenancy et policy
- Nats : queing
- cAdvisor : suivi de metrics de containers
- UI pour voir les workspaces terraforms
- kuik : gestion des images via kub
- kagent : agent ai au sein des cluster k8s, pour acter comme un gestionnaire de cluster, SRE
- CAPI : Cluster API, provisioning de cluster k8s depuis un cluster k8s
- HLS4ML : Portage de modèles d inference sur des FPGA pour usage real time
- SLURM : SLURM Workload Manager, un scheduler de workloads sur cluster linux.
- ORAS : Manage any artifact as an OCI container.
- Metal3 : Bare metal host management for k8s, base sur Ironic
- Ironic : Bare metal as à Service
- Kine : Permet de remplacer ETCD par un rdms autre.





