Deploiement LLM IA - Etat de l'art¶
Table des matières¶
- La représentation physique des LLMs
- La construction des LLMs
- L'utilisation des LLMs
- La personnalisation des LLMs
- Le hosting des LLMs
- La construction d'agents
- Multi Agents Systems
Lexique - Générale¶
Lexique Fondamental
LLM (Large Language Model) : Modèle d'intelligence artificielle entraîné sur de vastes quantités de données textuelles pour comprendre, générer et interagir en langage naturel.
Multimodalité : Capacité d'un modèle à traiter et à intégrer des informations provenant de différents types de données (modalités), comme le texte, les images et l'audio (par exemple, GPT-4o).
Réseau de Neurones (Neural Network) : Structure algorithmique inspirée du cerveau humain, composée de "neurones" interconnectés, qui apprend à partir de données. C'est la base des LLM.
Poids (Weights) : Paramètres numériques au sein d'un réseau de neurones qui déterminent la force et l'importance des connexions entre les neurones. Ces poids sont ajustés pendant l'entraînement et encodent la "connaissance" du modèle.
Embeddings (Représentations vectorielles) : Représentations numériques denses de données (mots, phrases, images, audio) dans un espace vectoriel de plus faible dimension, capturant leurs relations sémantiques. De façon générale, compréhensible uniquement par le modèle qui l'as généré.
La représentation physique des LLMs¶
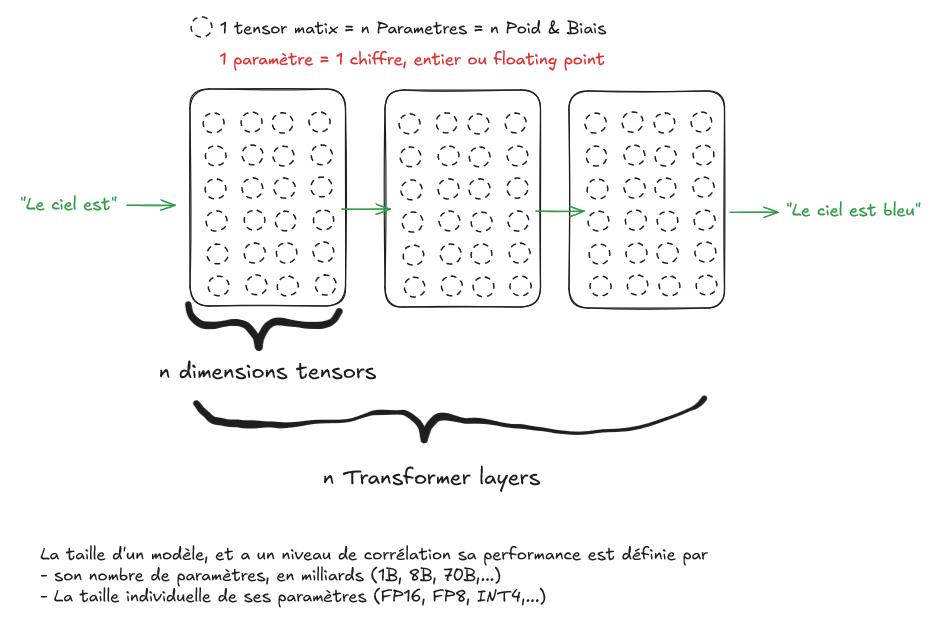
Les réseaux de neurones actuels dont les LLMs sont des successions de niveau de transformer qui portent les "couches d'intelligence", qui s'appuient sur des tensors (collections multidimensionnels, ex: un tensor 2D = matrice). Ces tensors sont représentées par des paramètres correspondant principalement a des Poids ou des Biais.
Si on prend des exemples de modèles open sources, sur hugging-face
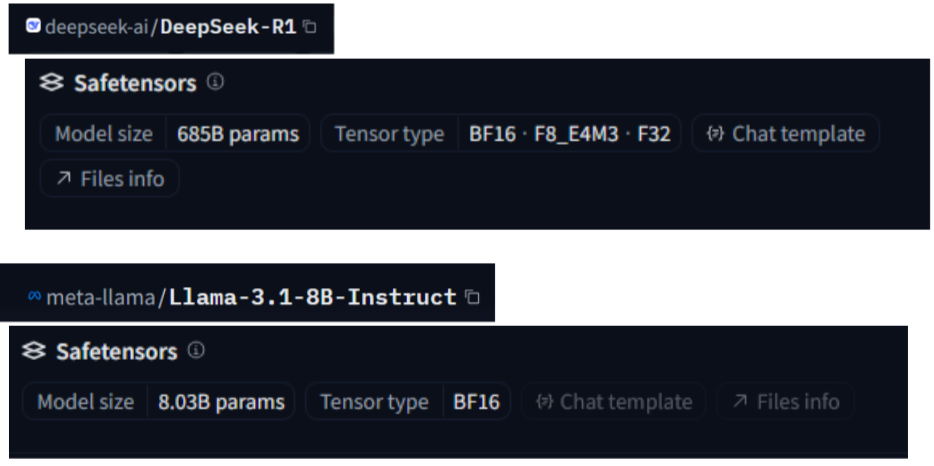
On voit par exemple pour Deepseek R1 : https://huggingface.co/deepseek-ai/DeepSeek-R1/tree/main
- Model size 658 Milliards de paramètres
- Tensort types : BF16 donc un floating point 16 bits , …
Cela représente dans le repository hugging-face, un modèle au format safetensors, 163 partitions de 4,3Gb, soit un modèle de ~700Gb a monter en mémoire GPU dans sa version non quantifiée.

Quantification (quantization)¶
Quantification
Le processus de réduction de la précision numérique utilisée pour représenter les paramètres (principalement les poids et les biais) d'un réseau de neurones, comme un LLM. (ex, passage de FP32 a INT8)
Si on effectue une Quantification par exemple en Q_4, qui transforme les floating point 16 bit en int 4 bit, on peut descendre a ~360Gb a monter en memoire GPU
On peut aller jusqu'à 1 bit!
Distillation¶
Distillation
La distillation de modèles LLM est une technique qui consiste à transférer les "connaissances" d'un grand modèle LLM, appelé modèle enseignant, vers un modèle plus petit et plus efficient, appelé modèle étudiant.
Un autre axe de réduction des pré-requis memoire GPU est de passer sur une version du modèle "distillé" c'est a dire avec moins de paramètres, exemple

On conserve des paramètres de 16bits, mais on passe a 32 milliard de paramètres contre les 685 du modèle "complet".
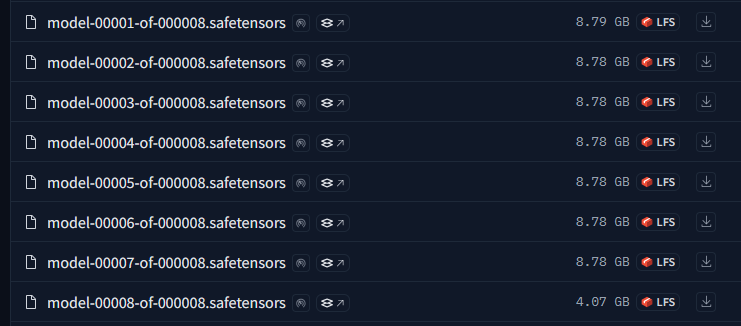
On a ainsi un modèle de "seulement" 70Gb a monter en mémoire GPU
La combinaison de ces deux techniques, quantization/distillation permet de servir des modèles puissant a différent niveaux d'efficacité sur des infra de tailles variables.
On se rend compte que quand si on dit je fait tourner Deepseek R1 sur mon Raspberry pi, ça ne veut pas dire grand choses, si on ne sais pas quelle distillation et potentielle quantification est utilisée.
La construction des LLMs¶
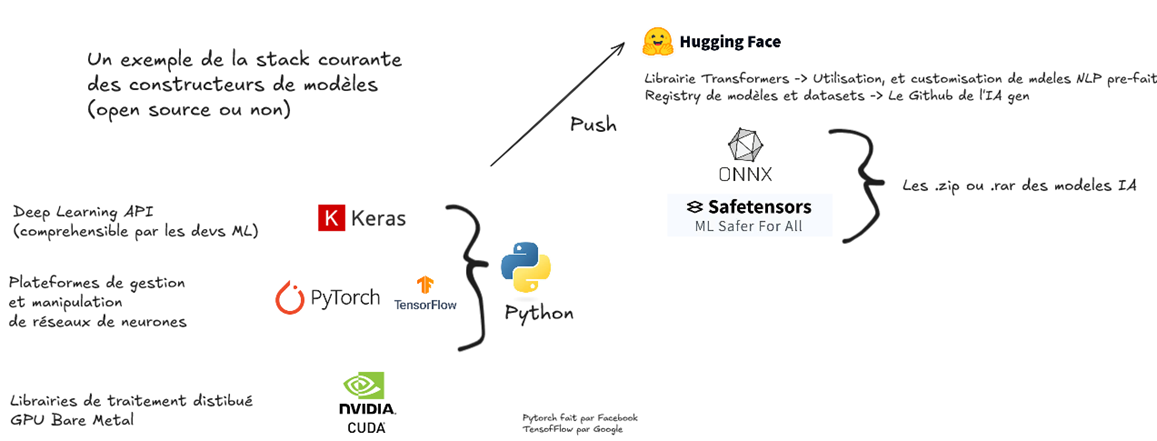
Toutes les applications AI, de haut niveau sont codées en python. La couche basse CUDA est codée dans un langage propriétaire proche du C, maintenue par Nvidia.
Les frameworks de manipulation et entrainement de réseaux de neurones sont développes par des Tiers, PyTorch par Facebook et TensofFlow par Google par exemple. Ces Frameworks s'appuient sur les drivers et librairies de parallélisation CUDA.
Les développeurs de LLMs utilisent un couche d'abstraction supplémentaire comme par exemple Keras, qui offre une API de gestion/expérimentations/entrainement de modèles deep learning. Cet plateforme est agnostique du backend et peut s'appuyer sur TensorFlow, PyTorch, JAX.
Lorsqu'on évoque un modèle "open source" (llama, deepseek,…), cela n'implique pas toujours que les jeux de données (data sets) et le code source d'entraînement soient intégralement ouverts. Souvent, ce sont principalement les poids finaux du modèle qui sont publiés, par exemple sous forme de fichiers .safetensors. Certains projets open source vont plus loin en partageant également le code d'entraînement voire les données.
Pour les modèles propriétaires, comme ceux d'OpenAI, la confidentialité de ces poids est cruciale et leur divulgation est généralement évitée.
Lexique - Construction des LLMs
Architecture Transformer : Type d'architecture de réseau de neurones particulièrement efficace pour traiter des séquences de données (comme le texte). Elle utilise des mécanismes d'attention pour peser l'importance des différentes parties de l'entrée. C'est le fondement de nombreux LLM modernes.
Encodeurs (Encoders) : Composants d'un modèle qui transforment les données d'entrée (texte, image, audio) en une représentation numérique (souvent des embeddings) que le reste du modèle peut traiter.
Tokenisation : Processus de découpage du texte en unités plus petites appelées "tokens" (mots, sous-mots ou caractères), qui sont ensuite converties en représentations numériques.
Datasets (Jeux de Données) : Collections de données utilisées pour entraîner et évaluer les modèles d'IA.
Autorégressif (Autoregressive) : Type de modèle qui génère une séquence d'éléments un par un, où chaque nouvel élément est prédit en fonction des éléments précédents (par exemple, la génération de texte ou d'images par GPT-4o).
Modèles de Diffusion (Diffusion Models) : Technique de génération (souvent pour les images) qui commence par du bruit et le raffine progressivement pour créer une image cohérente, guidée par un prompt.
L'utilisation des LLMs¶
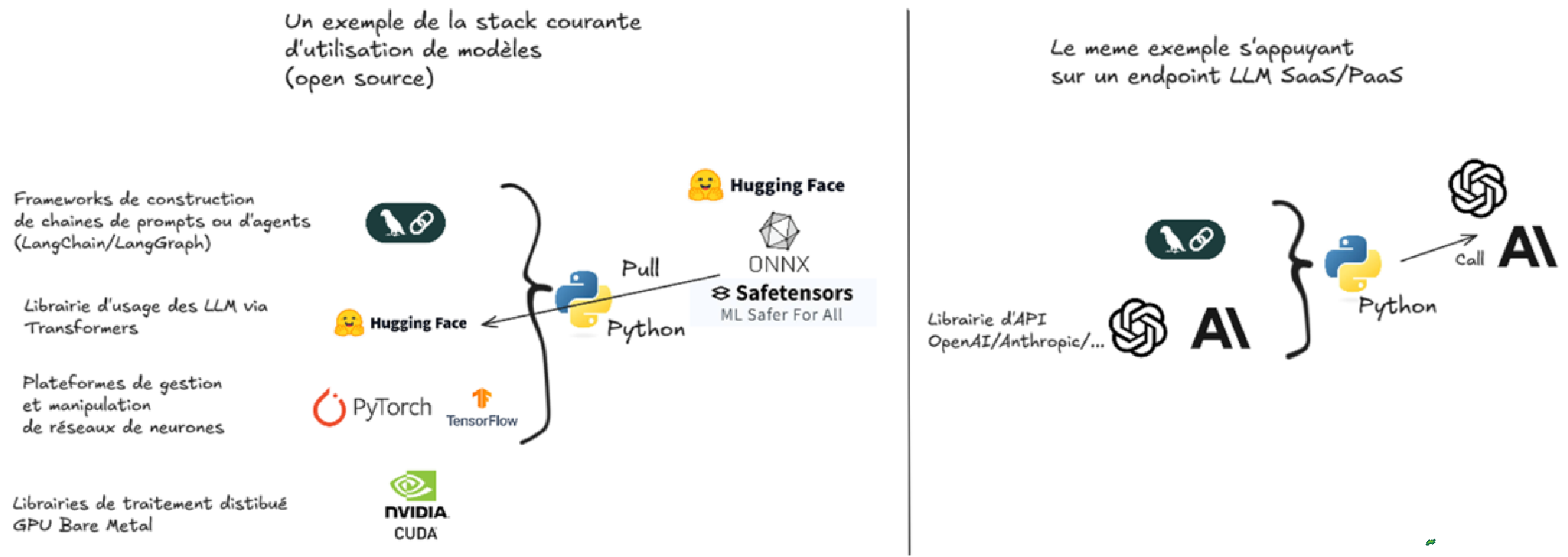
On voit bien ici qu'une fois qu'on abstrait le serving du LLM, en passant par un endpoint centralise ou externe, les besoins applicatifs sont beaucoup plus simples.
Lexique - Utilisation des LLMs
Inférence (Inference) : Processus d'utilisation d'un modèle entraîné pour faire des prédictions ou générer des sorties à partir de nouvelles données d'entrée.
Langchain : Framework qui facilite la construction d'applications alimentées par des LLM, en permettant de chaîner des appels de modèles, de les connecter à des sources de données externes, et de créer des agents.
Modèles Open Source : Modèles dont les poids, et parfois le code d'entraînement et les datasets, sont publiquement disponibles et modifiables (par exemple, stockés sous forme de fichiers .safetensors).
Modèles Propriétaires : Modèles développés et contrôlés par des entités privées (comme OpenAI), dont les poids et souvent l'architecture détaillée ne sont pas publiquement divulgués.
La personnalisation des LLMs¶
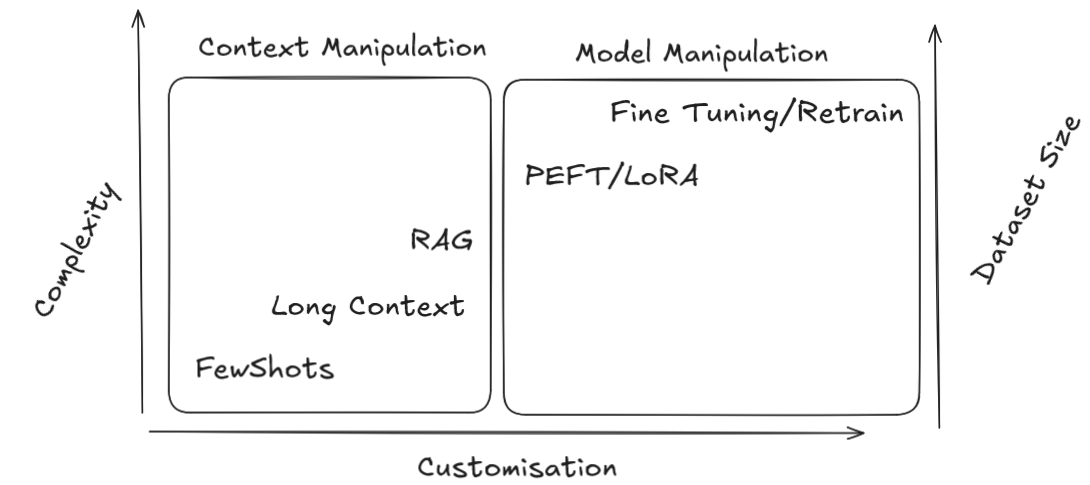
Lexique - Personnalisation des LLMs
ZeroShot : On donne un rôle et des instructions au LLM via le system prompt, sans exemples.
FewShots : On donne des exemples de question/réponses dans le contexte avant la vraie question, pour guider le modèle.
Long Context : Tous les documents a connaitre sont attachés au prompt en plus de la question.
Retrieval Augmented Generation : Une recherche est faite en base (souvent vectorielle) pour ajouter les contenue des documents pertinents au prompt
PEFT/LoRA : Un "addon", sous forme de poids aditionels / petit modèle est entrainé sur un dataset restreint, pour biaiser le comportement du modèle de base utilisé au moment de la géneration, qui lui reste inchangé.
Fine Tuning/Retrain : Des iterations (epoch) d'entrainement supplémentaire d'un modèle de base(checkpoint) sur un dataset plus ou moins large, pour biaiser le comportment du modele de base.
Le hosting des LLMs¶
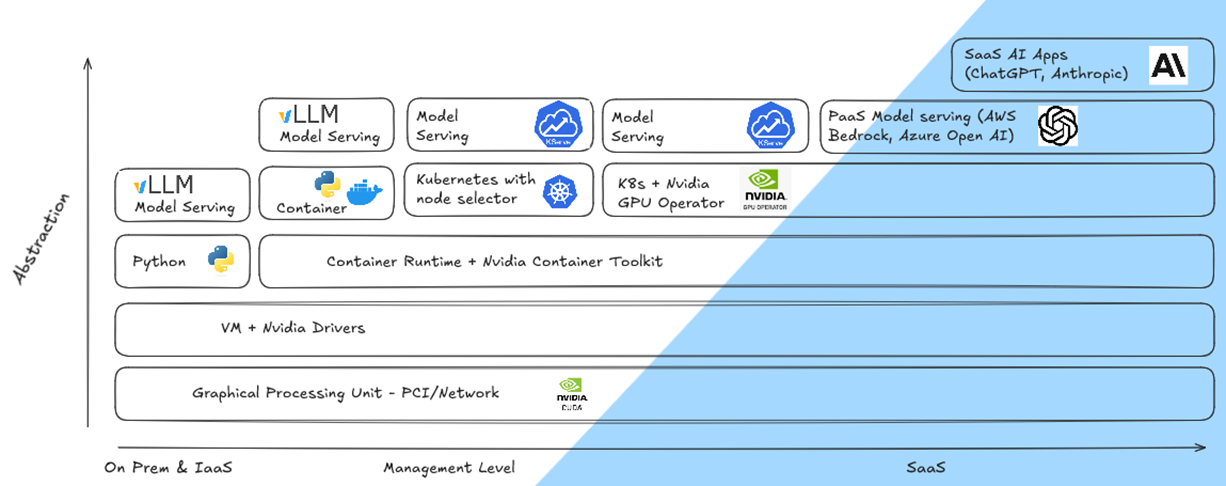
Bien que des acteurs et projet concurrent commencent a émerger (Intel Arc, AMD Rocm), on voit sur le marché l'omni presense des solution Nvidia, sur la plupart des couches structurantes de l'écosysteme IA. Du bare metal, au librairies Python, en passant par les environnements conteneurisés, cela est principalement du a la stack CUDA, qui fait office de kernel entre les librairies/framework, et les couples de CPU + GPU Nvidia. (d'où les stonks📈💸)
Le management des couches On prem et IaaS est assez similaire, a partir de la couche VM, l'important est de gérer la continuité de driver Nvidia, de bas en haut.
Pour du serving en conteneur Simple ou directement en Python, on utilise des librairies tel que Vllm, qui apportent de la simplicité.
Une fois qu'on est dans le spectre Kubernetes, on privilégie des solution plus adaptées et Cloud Native, tels que Kserve.
Les Solution PaaS et SaaS, même si on ne le voie pas, se basent sur des couches inferieurs très similaire, et les optimisent grâce a la multitenancy native de leurs déploiements. Ce qui leur apporte un avantage financier, car il est difficile d'utiliser « au taquet » des infra GPU on prem ou dédiées de taille suffisants au hosting de modèles modernes. (200GB VRAM+)
La construction d'agents¶
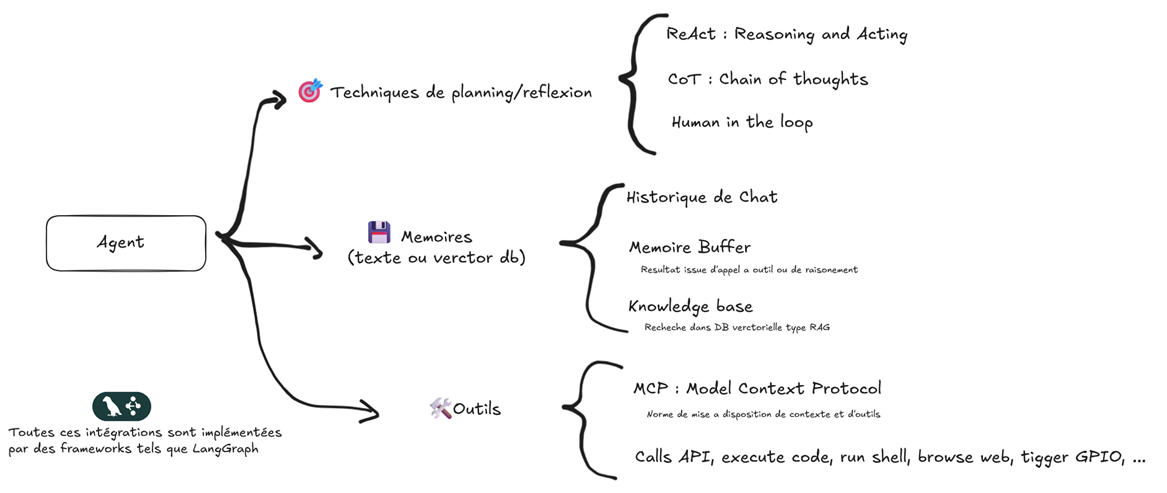
Multi Agents Systems¶